
Why not just use Providence's Open Data Portal?
Providence helpfully hosts a property tax spreadsheet here. The spreadsheet separates the owner's first and last names (see below why this is so important). Unfortunately, the spreadsheet did not have all of the information I wanted, such as square footage, acreage, and parcel id. The OWNER_COMPANY field seems like it would've been helpful, but it's not consistently applied (with a lot of first / last names being businesses), so I would've had to scrape this, anyway, for accuracy.
What are some problems with the assessment data?
Providence's Vision page, unfortunately, does not standardize data entry. That is, names do not appear in a repeatable FIRST | MIDDLE | LAST format. They usually are like that, but they can also appear in various ways, such as,CARLOZZI MICHAEL J
CARLOZZI MICHAEL JOHN
MICHAEL J CARLOZZI
MICHAEL JOHN CARLOZZI
CARLOZZI JOHN MICHAEL
These inconsistencies fluster name classifiers. Since the name Carlozzi Michael is obviously not Michael Carlozzi, guessing the name bearer's race becomes harder.
I had coded the names as FIRST (omit middle) LAST or LAST FIRST (omit middle) if the last word was one character (i.e., the middle initial). I had hoped that this would suffice, but after wading through the data I noticed that misclassifications would result in an upward bias for Non-Hispanic White names. That was because the classifier, when encountering non-standard first names, appeared to default to Non-Hispanic White. Consider the name OSCAR PEREZ, which the model believes has a 92% chance of being Hispanic. It believes, though, that the name PEREZ OSCAR has just a 4% chance of being Hispanic, a 57% chance of being Black, and a 39% chance of being Non-Hispanic White. In other words, the model's confused (understandably so, as the name should be OSCAR PEREZ).
This meant that I had to sift through every single row of data (over 30,000) and fix the names. Obviously this took a lot of time, and I have not yet finished, and I have also missed names as my eyes inevitably glazed over. Still, I have corrected most of the names. I probably should have matched names with Providence's formatted Open Data spreadsheet.
Yeah. You should probably do that if you're interested in name-based analysis.
How does a name classifier work?
Ethnicolr is a machine-learning classifier that estimates a probability of a name belonging to one of four categories: Asian, Non-Hispanic Black, Non-Hispanic White, and Hispanic. For this analysis, I used the model which had been trained on Florida's voting registration data.
In my maps, the results show the percentage chance, in the model's estimation based on Florida's voting registration data, of an individual home owner being Non-Hispanic White. So, for example, my name has a 98.7% chance of being Non-Hispanic White. The name Max Porter has an 80% chance of being Non-Hispanic White, with an 18% chance of being Black. On the other hand, the name Samnang Som has a 99% chance of being Asian and thus a less than 1% chance of being Non-Hispanic White.
It's important to understand what this means and what it doesn't. Note that I specified individual homeowners. Many homes are owned by companies and not individuals, and those are not captured here. Despite America's psychopathic recognition of corporations as people, they actually are not people, and, therefore, cannot have an ethnicity assigned to them. So, while we may assume that many white people own these companies (or own shares in the companies), I hold off on making this explicit. Like, this company owns many Providence multifamilies, especially on Smith St., and its team looks very, very white. But they, and other companies, are excluded here, so we are undercounting white property ownership..
It also does not mean that's who necessarily lives in those properties; they may not be owner-occupied at all.
There are obviously many limitations that I'd like to discuss, and having spent several thousand rows in a dataset getting to know ethnicolr, I've begun to understand its thought process. But I first want to explain why I chose this classifier as opposed to another.
A competitor was rethnicity, which boasts a much better success rate at predicting persons who are not Non-Hispanic White. I was happy to see that; ethnicolr's authors acknowledge that it struggles to predict non-white persons. However, it seems like rethnicity does this at too much a cost. For instance, I think that I have a very Non-Hispanic White name, being fully Italian-American. Rethnicity believes, however, that I have only an 86% chance of being Non-Hispanic White. Consider the Irish name GREG SHEA, which the model estimates has a 38% chance of being Non-Hispanic White; the model would have us believe that, if we encounter a random person named GREG SHEA, we should guess that this person is Asian (55%). Even GREGORY SHEA does not fare much better, with a 73% chance of being Non-Hispanic White.
So, with that, I picked ethnicolr.
I chose its Florida dataset for two reasons. First, it uses both first and last names. As is well-known, predicting ethnicity from last names is challenging for all persons but especially people of color because they have surnames in common with Non-Hispanic Whites. Second, Florida has a large Hispanic population, and so does Providence. I had hoped that this would make our city easier to classify, and I am happy to say that the model appears to do a good job of classifying Hispanic sounding names (I say "appears" because I have no way to externally validate the names except by saying, yeah, OSCAR DE LA HOYA does sound "Hispanic").
I mapped the probability of being a Non-Hispanic White person for two reasons. First, it was of interest to me what share of property (and types) this demographic owned. We know that Providence is a segregated city where its super minority of Non-Hispanic White people (approximately 33% of the total population) wield considerable power and influence. I wanted to examine how this segregation materialized in property ownership, and for my interests it did not much matter if a Nigerian or Laotian or Guatemalan owned property--only that a non-white person did.
Second, while ethnicolr did, I believe, a good job separating white people from non-white people (to the extent this can be done on the ambiguity inherent in names), it struggled to differentiate among the other categories. Sometimes it would classify Arabic-sounding names as Asian; this can make sense if we consider the Middle East as part of Asia. But then it would believe a Nigerian name was also Asian. And, all right, this can make sense if we interpret Asia as basically anywhere in the world that's not the Americas, but this isn't a very reasonable approach to take.
In my opinion.
For those who'd like to analyze ownership from the perspective of other ethnicities, I would consider ethnicolr's Wiki dataset, which is far more granular; the Florida's data, in contrast, are simply too crude, lumping everyone together so there's no difference among Japanese, Chinese, Korean, Indian, and Nigerian names. To me, that's functionally useless.
What else did the model struggle with, and why did I have to babysit it by combing the spreadsheet? In addition to the name order problem above, it struggled to recognize African names. Nigerian names are not all that common in Providence but they do occur, and the model would almost always believe they were Non-Hispanic White. However, when I switched the first and last names, the model believed instead that the name was very likely to be Black. The same phenomenon occurred with Indian names. For these names, I felt it was more appropriate to deviate from the FIRST LAST name model in favor of a LAST FIRST name one because, if nothing else, it brought down the Non-Hispanic White bias.
Although the model did well at classifying Hispanic names (I think, anyway), the lack of standardization made this difficult. For example, consider the name OSCAR DE LA HOYA. I had programmed the model to ignore the middle initial, but this would convert the name to OSCAR LA (I cut off after the third word because often irrelevant words like TRUSTEE followed). This is obviously wrong, so I had to manually correct it (again, I should have matched my spreadsheet with that on Providence's Open Data Portal).
Then comes the question of what to do with a name like JUAN VALDEZ ROMERO. Because I had ignored middle names, this meant that the model had to see JUAN ROMERO, which has a lower chance (though still high) of being Hispanic. But I could not just include VALDEZ, because the model was not setup to process middle names. The model would, instead, understand it as an unusual first name JUAN VALDEZ. You can't just throw extra names in there and expect the model to understand what's happening. This sort of balanced out, because it meant I also dropped middle names that would make names more likely to be classified as Non-Hispanic White, so it was not a bias which only affected one group.
But maybe VALDEZ ROMERO is the last name. For example, the last name for CASTILLO JUAN FELIPE R probably has two words in it, because this name format almost always had the middle initial last with the first name immediately preceding: here, FELIPE R. This means that JUAN CASTILLO is probably the last name and "R" the middle initial: FELIPE | R | JUAN CASTILLO. Anyway, by manually reviewing the spreadsheet's entries, I was able to make these sorts of adjustments.
Here are some boxplots from ethnicolr's model
The first is of the probability of being Non-Hispanic White and the second the probability of being Hispanic, by property type.
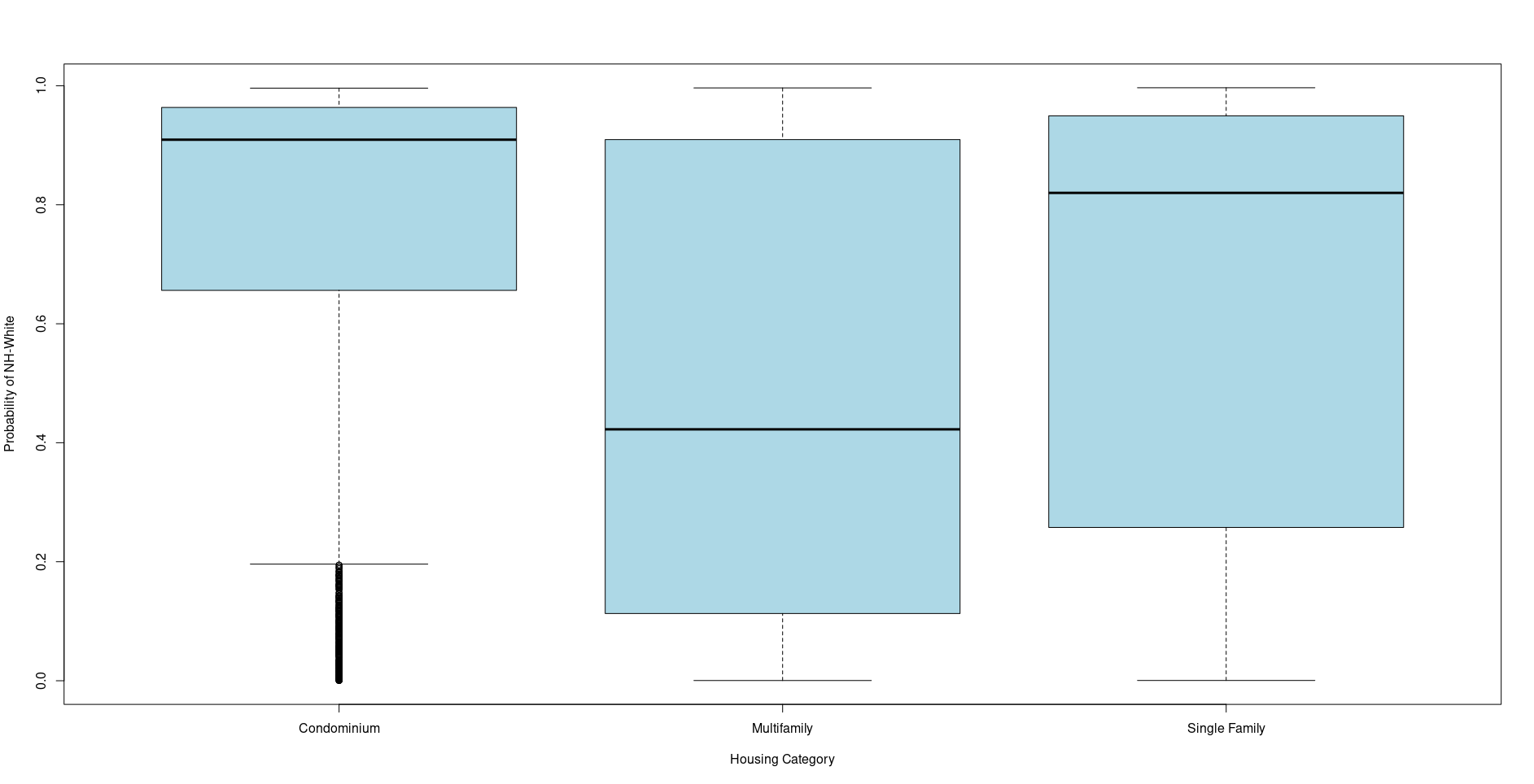
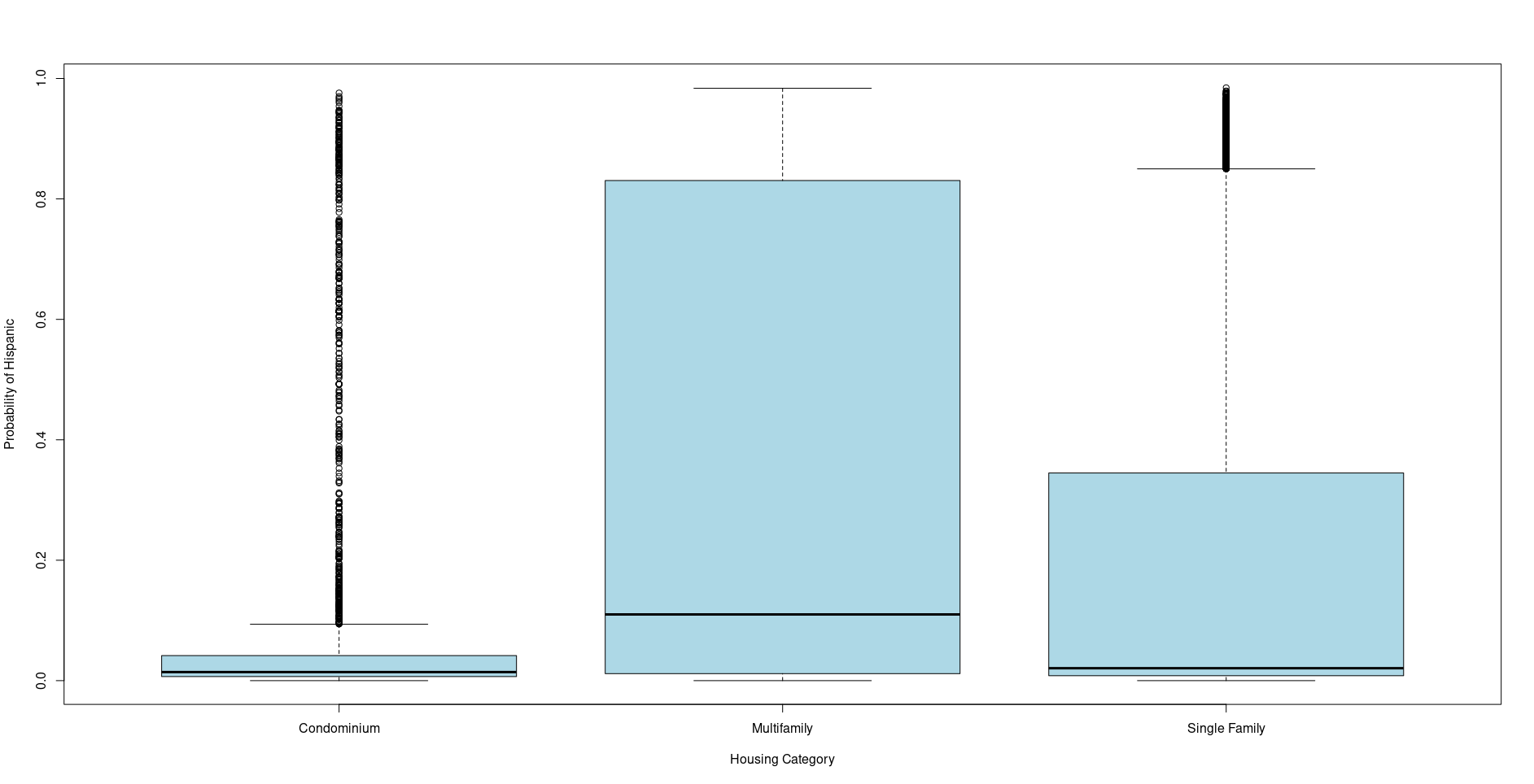
I'd like to do my own analysis. What should I watch out for?
Addresses in the database don't always match up with what a property uses. For example, Southlawn Palm Apartments uses 116 Evergreen St., but Providence records it as 229 Camp St.
Further, Providence doesn't always categorize properties correctly. Well, maybe it makes sense in their system, but it doesn't make much sense to me to label what's clearly commercial property as industrial.
Hey! I know such and such property and it's not vacant (or commercial or industrial or whatever)!
Take it up with Providence. They classify this stuff. Sometimes I fixed clearly misclassified properties but, given the volume of entries, I only examined those with higher acreage, and even then I probably missed some. And sometimes records had obvious errors, like registering 69 Wild St. as having 15.06 acres of vacant land when it's probably 0.06 acres, but I obviously cannot detect all such errors..
Vacant classifications can require judgment calls. You can't simply add up all of the "vacant land" because Providence uses "vacant land" to mean "something without a building on it." So, a useful (to the extent such a thing can be useful) parking lot is "vacant land," but that's not vacant land, I think, in the sense that we'd like to discuss it: land with no purpose other than being land, whether for someone's aesthetics or convenience or "investment strategy."
Because of the volume, I took Providence's word and classified something as vacant when it expressly had vacant land in its classification, such as Vacant Res Land. Then I reviewed some smaller categories and manually classified each property; these categories were "ACC Comm Lnd" and "Comm OBY," which were very often parking lots or outbuildings but sometimes true vacant land.
A natural question is whether I'm under or over-counting vacant properties and land. I think it's more of an undercount because I did not include any of the obviously vacant properties that were classified as commercial (or something), despite being little more than a fading sign begging someone to buy the land.
To be fair, some vacant properties did not look very vacant to me, in that there appeared to be something on them, so these properties balance somewhat those which were not counted.
That's not where my house is!
GPS coordinates are address-based and so not quite exact. Also, if Providence's assessors entered an address wrong (like entering AVE instead of ST) then the GPS finder may have selected an address in another municipality. I manually fixed all that I could find, but some flew under the proverbial radar. And, actually, I now notice an address way out in right field on the single family map on the main page. This was especially problematic with vacant properties, as the GPS finder skipped over many Providence addresses in favor of (habitated) properties in other municipalities. The assessors also did not enter complete addresses for some of these properties. In any event, these were very few addresses.
R code for finding owners
Data here assumes prov is the datafile, e.g., prov <- read.csv("prov_master.csv"
The matching variable is a list of all known addresses used by the owner; the ones here are for Paolino; "x 1576" is shorthand for PO BOX 1576. You want to put as few characters as possible so you don't miss typos or inconsistencies. So if I put down "PO BOX 1756" and Providence entered it as P.O. BOX or PO Box (two spaces), I would miss it. I will still miss "PO BOX 157 6," but that seems like it'd be much rarer.
matching <- c("300 glenwood","100 Westminster","100westminster","100 westminster","76 dorrance","76 dorrance","75 dorrance","75 dorrance","x 1576")
#we have two 76/75 dorrance entries because one of them has an extra space; this does not translate to the html code
owner <- subset(prov,grepl(paste(matching,collapse="|"),owner_address,ignore.case=TRUE))
unique(owner$owner)
to_remove <- c("Antoinette")
owner <- subset(owner,!grepl(paste(to_remove,collapse="|"),owner,ignore.case=TRUE))
You'll want to see the owners with the unique() call and cross check them against the Secretary of State's records, because you do sometimes get mistakes. Here, we mistakenly pulled one record who used 100 Westminster but at Suite 500; we removed the owner's name ("Antoinette") in the to_remove variable. On the Secretary's page, pull the official paperwork and check names of the owners and partners: all that basic bureaucratic forensic stuff.